How browser renders websites?
If asked, “How do browsers render websites?” you could have answered: Browsers take HTML and use CSS as styles. There are JS scripts for actions, and the browser typically interacts with the DOM.
Well, it’s not incorrect, but it’s just the tip of the iceberg! Let’s uncover some facts and learn what’s happening behind the scenes!
〝The most important part of a web is not the webpage but the browser.
〞
What is a browser?
Simply, it is just a software that loads some files from a remote server (or from your computer/system). The files can be txt, html, json, or even csv. The browser is capable of displaying or rendering most of the files. How it is displayed is the interesting part.
Browsers use a browser engine to determine how to render which types of files. Gecko , which is used by Firefox or Blink , which is used by Chromium (Chrome-based browsers), or Webkit which is used by Safari, Apple are some of the popular browser engines.
You can even check the comparison between browser engines.
Let’s unleash how websites (typically made using HTML, CSS, JS, React, etc) are rendered on the browser.
Stage: DOM
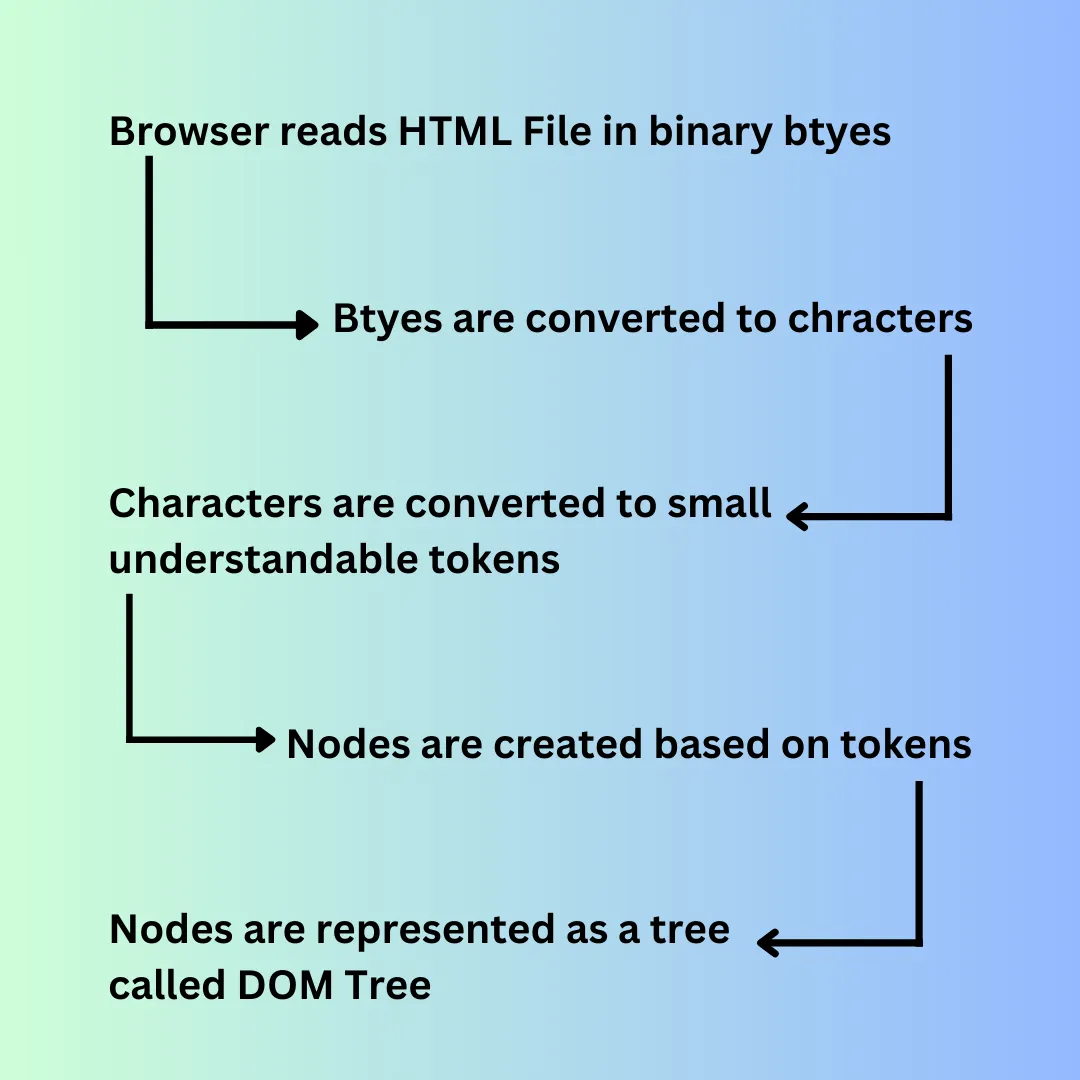
Whenever the HTML files are loaded by the browser, be it locally or remotely. The browser first reads the file in the form of binary bytes. Those byte chunks are converted into characters. Those characters are still useless for browsers. So, at this point, tokenization happens.
Tokenization is a way of breaking the whole characters into smaller and separated tokens that can be understood by the browsers.
For example, look at the below tokenization of the JavaScript code.

In HTML, tokens are separated using tags i.e. <>, </>.
Using the tokens, nodes are being prepared. Nodes are the objects in the memory with the information of the HTML tags. Each node has properties, and they are distinct from each other. These nodes are used to represent a hierarchy of the whole HTML page. This is done with the help of Data structure. This data structure is known DOM (Document Object Model) tree.

Now these DOM trees will be rendered on the browser, and it's done? Nope, there is much more to it!
Stage: Render Tree
DOM Structure is built, but what about CSS? And so here comes CSSOM in the picture! CSSOM is a CSS Object Model just like DOM for HTML. The process is almost identical for CSS files too. The browser reads CSS files byte by byte, then it is converted into characters. Tokenization happens, and tokens are made. Then, it creates unique nodes and is represented with a CSSOM tree data structure. Let’s talk about CSSOM.
〝Have you ever wondered what does Cascade in Cascading Style Sheets means?
〞
CSS follows a cascading algorithm that determines which type of styles to apply on which element. There might be cases where the style of an element is affected by the style of a parent element. Or there may be multiple styles for the same element, so what style to override or what styles an element gets is determined by the cascading algorithm.
So now the browser has two trees, DOM & CSSOM. These are then combined, and then a render tree is prepared.
〝Render Tree = DOM Tree + CSSOM Tree
〞

The render tree contains all the nodes that need to be displayed. So, for example, if there exists a div element with display:none as style:
<div style="display:none">Hidden element</div>Then, this element will exist in the DOM tree, but it won’t exist in the final render tree as it is not displayed. You can also see in the above diagram where the span tag that exists in a DOM tree that has a style display:none and thus it is not included in the render tree.
So the render tree, a combination of the DOM tree and CSSOM tree, is displayed on the browser, and that’s all? Nope, there's more to it!
Stage: Reflow
Once the browser makes a render tree, the next step is to design the layout of each element that exists in the render tree node. We have an element, its content and its styles, so at the layout stage browser designs the layout of each element on the browser viewport. Here, the size and the exact position of each element is calculated. The layout is made for each device viewport (it can be a mobile screen, a tablet, or a desktop).
Stage: Painting
We have all the visible elements, content, and styles and even have it’s exact sizes and positions. Now, it’s time to paint the element and render it pixel by pixel on the screen. This is the hardest step for any browser as browsers have to do a lot of things to render the elements. This step also includes displaying colors, loading fonts, and applying typography.

JavaScript Is Costly
Website is not just HTML and CSS. JavaScript (which people refer to as the brain of a website) is widely used in web development. But JavaScript comes with a cost. Integrating JavaScript with HTML file needs the additional network resource to download that script.js file, and it affects the DOM creation too.
Whenever a DOM tree is created and if the browser encounters a <script scr="script.js"></script> tag, the DOM creation is paused and halted at that point. Why? Because JavaScript has the ability to manipulate the DOM elements. The browser first reads the content of the JavaScript file, then the DOM is resumed, and changes are made based on both the HTML and JS content.
〝This is why, it is advised to place the script tag after the body or at the bottom of the document, to not affect the DOM creation.
〞
If you try to put script tag at the start of the document (e.g. inside the head tag) and you try to access the DOM element which is present inside the body tag, you will not be able to access it because the DOM is not created fully and is paused as script tag is encountered. See the example below.
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <script> let content = document.getElementById("name").innerText; alert(content); // Not accessible. </script> <title>Example</title></head><body> <h1 id="name">Hi, I am Noor!</h1> <div>I am a div tag!</div></body></html>Here, the alert will not be created because the element <h1> with the ID name, the script is trying to access is not created yet!
This matters because if there happens to be a heavy JS file where lots of computation is going on, and multiple functions are being called, then using JS at the start of the document will delay the DOM tree preparation, which will eventually slow down the website rendering and website will appear to be slow.
But in the case of CSSOM, it is different. In most browsers, while the CSSOM tree is being prepared and a script tag is encountered, the CSSOM tree will not pause; instead the JS file reading is paused until the CSSOM tree is fully prepared. Then, the JavaScript content is read, and if there is any style manipulation in JavaScript, it is taken care of before creating a final render tree.
At a senior-level position, such information matters. We need to understand when the DOM tree is constructed, when the JS file is loading, what is the byte size of the JS file, and what process can be delayed to reduce the latency of our webpage as low as possible to load the website much faster.
If you've enjoyed reading this blog and have learnt at least one new thing, do subscribe to recieve updates whenever I post a new article directly to your inbox and do share on Twitter with your friends.